Skim
Skim is a terminal-based text filtering program inspired by fzf, but written in Rust with some additional features. One feature I truly appreciate is the --regex option. While fuzzy matching algorithms are often the quickest and easiest way to find data in a large set, there are frequent instances that I want more granular control of the matching, either to compare a range of values or find specific characters that fuzzy matching does not allow. I think fzf should adopt some of the features present in sk.
When investigating events or debug data in a shell, piping raw data into an editor like vi is useful, but often there are actions or tools that you would like to run subsequent to the original data output. The preview window can dispatch additional processes to gather additional data to give you a larger context. This can be a simple shell command, or a list of commands.
I've saved some examples below in the form of bash scripts, along with screenshots showing the interface and supplemental output from the preview window.
Data Filtering Examples
#!/bin/bash
# Filter and search SQL http log data into skim, using the preview window
# to execute a secondary query to provide further details for each country code.
# The JSON output is from clickhouse, and piped into jq for color and readability.
clickhouse client -q "select count(distinct client_ip), client_country from logs.http \
group by client_country \
order by count(distinct client_ip) \
desc limit 100" | \
sk --no-sort --regex --preview "clickhouse client \
-f PrettyJSONEachRow \
-q \"select distinct(client_ip), count() from logs.http \
where client_country = {2} \
group by client_ip \
order by count() desc limit 100\" | jq -C ."
#!/bin/bash
# Use SQL output to perform reverse IP lookup as you browse
# common connection source addresses
clickhouse client -q "select distinct(client_ip), count() from logs.http \
where client_country = 'cn' \
group by client_ip \
order by count() desc" | \
sk --no-sort --preview "dig -x {1}"
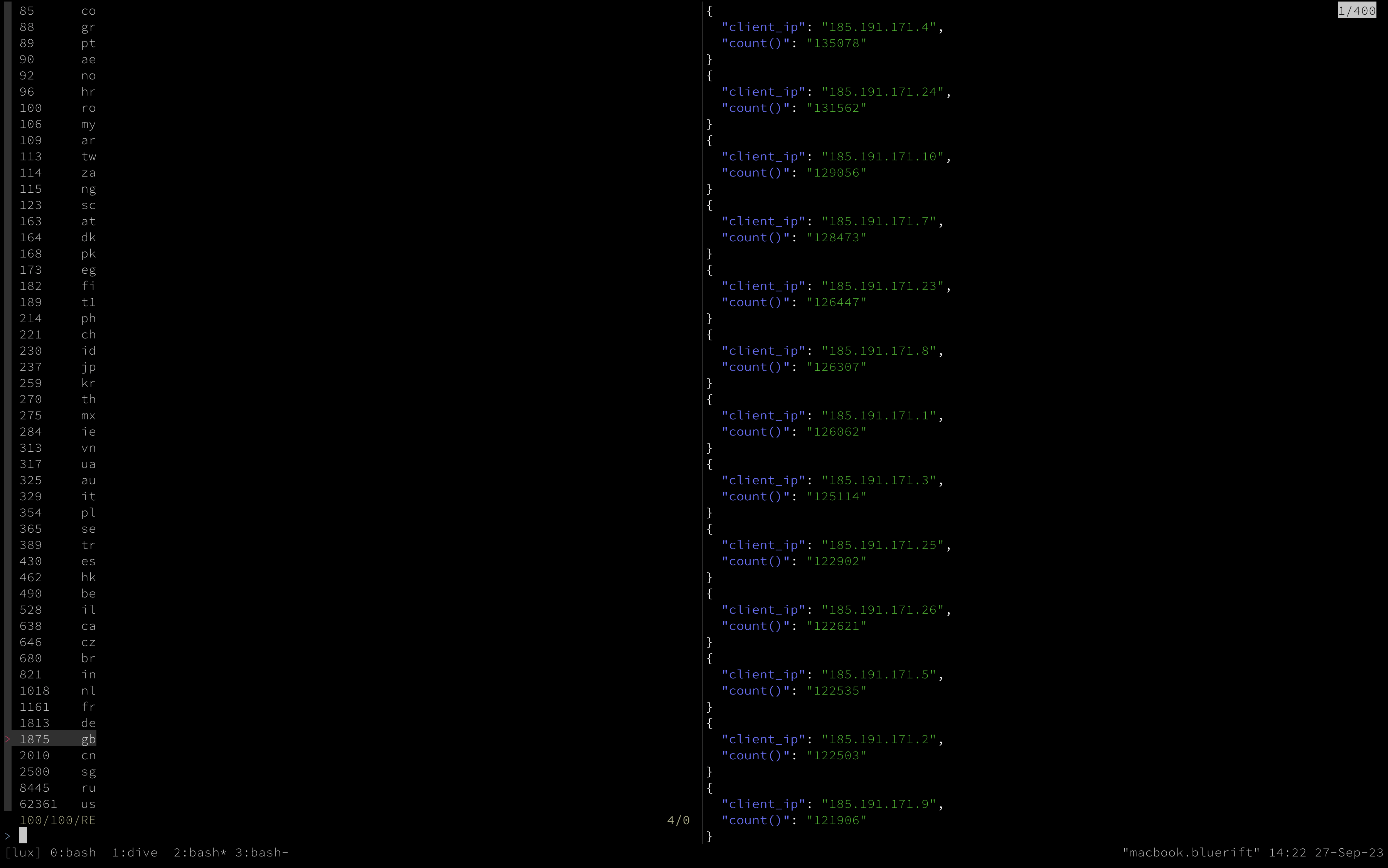
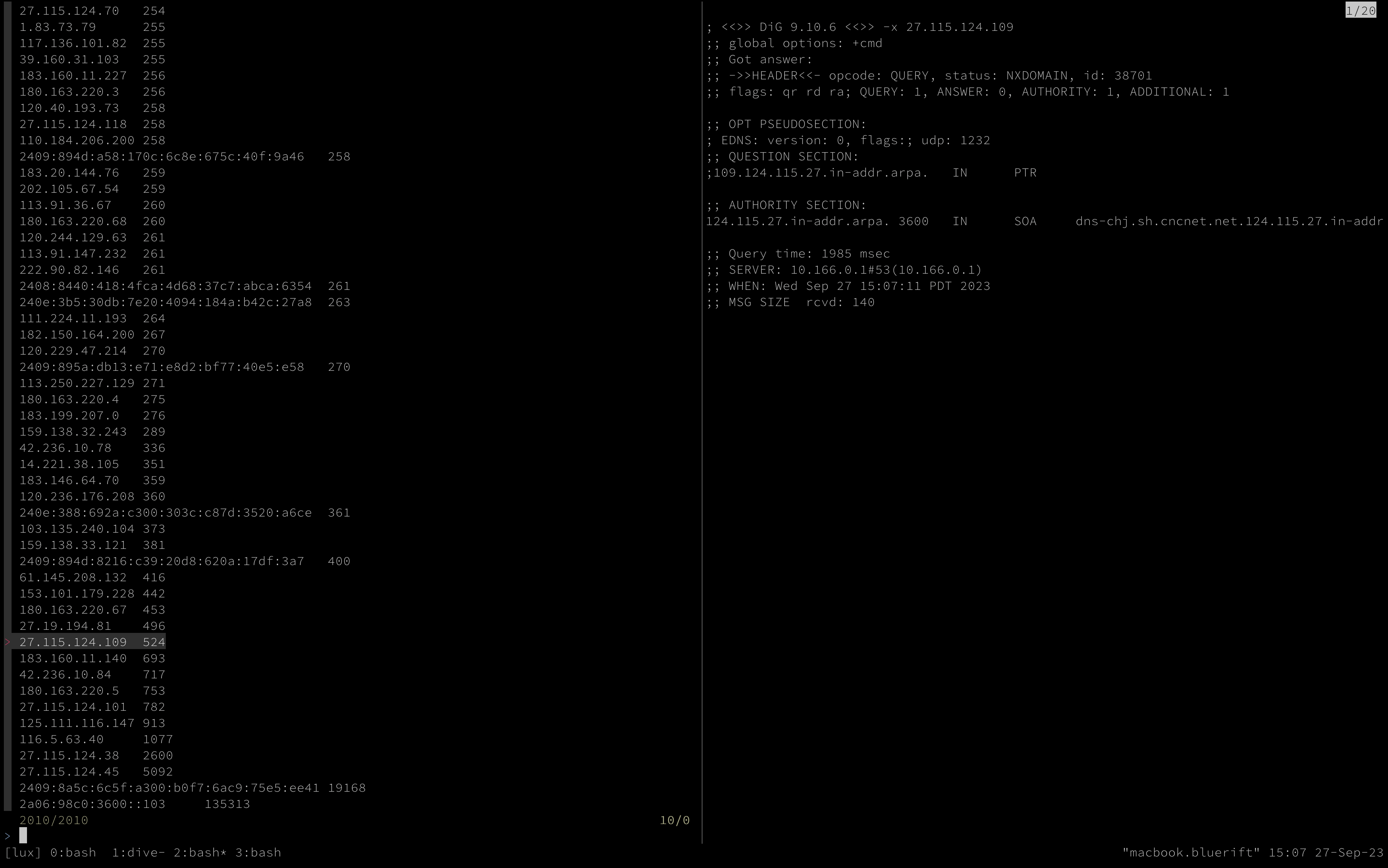
Using the tool in this way offers several benefits. When you are working to make sense of logs or other data, performing additional actions for each data point can become complex in the shell, often requiring process management and additional subshells, which may or may not have access to parent shell environment data. Jumping over these hurdles is possible, but often more involved until you have a greater grasp of what the data indicates. Building another set of tasks to run on a group of results can be more work when finding information about a few outliers can change your entire approach.
skim and fzf are incredible tools not just for software development, but especially for working in devops, containers, raw API responses, etc. These tools have actually been around for years, but haven't really made a large splash until the last few years. I wish I'd learned about them even sooner.